嫌弃Hadoop?可能是你的打开方式有问题
关于 hadoop 所谓的消亡,以及它跌落神坛的报道数不胜数。有很多人放马后炮说,Hadoop 从一开始就没有意义。还有人说“Hadoop 对于小型,临时的工作来说很慢”、“ Hadoop 很难”、“ Hadoop 已经死了,Spark 才是胜者”等等。那么事实真的如此吗?
如今围绕着 Hadoop 缺陷的争论和当初对其的大肆追捧一样激烈。
在这些喋喋不休的争论中,你可能已经得出结论,Hadoop 已经死了。个人认为这个想法虽然可以理解,但却是错误的。

TCP/IP
你听过 TCP/IP 吗?如果没有,相信我这是很强大的技术。实际上,你很喜欢TCP/IP ,你只是没有意识到。TCP/IP 不仅能驱动互联网,还能驱动电子邮件,甚至能驱动网络。当你使用各种应用程序,使用各种流媒体,以及打车、上网等等,这都受益于 TCP/IP,没有它你可能无法生活。
虽然你喜欢 TCP/IP,但是你对配置它不感兴趣。你不用输入 ifconfig 这样的命令,从而查看你的 WiFi 适配器是如何联网的。甚至你不用关心它附加的网关,以及它使用何种 DNS 服务器。
在 20 世纪 90 年代,TC/IP 曾被当做产品销售,结果不温不火。最终,TCP/IP 已被建立在操作系统中,如今到处都有它,TCP/IP 成为了普遍的标准。
Hadoop是基础设施
其实,Hadoop 就是大数据世界中的 TCP/IP。它是基础设施,同时也带来巨大的好处。但是,当基础设施暴露出来时,带来的好处就大大削弱了。Hadoop 像Web 浏览器一样被推广,但是它更像 TCP/IP。了解这一点时就会发现,推广 Hadoop 本身就不是个好主意。
如果你直接使用 Hadoop,那么你错了。如果你在命令行中输入“hadoop”和一些参数,那么你就在倒退。你是想自行配置和运行所有内容,还是只想使用数据,让分析软件在后端处理 Hadoop?
大多数人会选择后者,但大数据行业往往把客户导向前者。之前,行业是这么看待Hadoop…如今也将这么看待 Spark 和众多的机器学习工具。这是技术专家讨好商业用户的例子,这永远不会结束。
开发工具不等同于商业工具
业界并不是完全忽视这个问题,一些厂商已经在尝试改进 Hadoop 的不足之处。目前已出现 Hue、 Jupyter、Zeppelin 和 Ambari 等的开源项目,旨在让 Hadoop 从业人员摆脱命令行。
但问题就在此。我们需要为商业用户,而不是为Hadoop 从业者提供工具。Hue 非常适合运行和跟进 Hadoop 任务,以及使用 SQL 或其他语言编写系统查询。相比Spark,Jupyter 和 Zeppelin 非常适合编写、运行代码,以及使用数据科学的 R 和Python 等语言,甚至生成代码的数据可视化。问题是使用这些工具不等同于脱离命令行;它们只是让人们更有效地做这些事情。让人们完全脱离命令行是一回事,但让人们更简便的做同样的事情,并没有什么本质的改变。
BI 工具供应商也尝试改善这一现状。但他们通过简化 Hadoop,并将其当作 SQL 数据库来处理。给 Hadoop 加抽象层是好的,但是在它们之间加 SQL 层并不是。想做大数据分析吗?选择一个使用 Hadoop 的工具,并充分利用它。虽然你不用直接使用 Hadoop,但你的分析工具应该与它密切相关,而不是敬而远之。
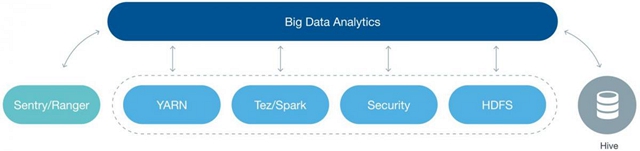
如果你还没有找到答案,这里有一个平衡的方法。从事大数据分析,你不用直接用到引擎——本文指 Hadoop,但你仍然需要它的全部效能。为了实现这一目标,你需要一个技术的分析工具来驾驭该技术,而不会否定或忽略它。在技术工具和 BI 用户之间有重要的中间地带。找到它,你将走上正轨。
Hadoop的前景
Hadoop 没有死,这毋庸置疑。Hadoop 是非常强大的关键技术。但它也是基础设施,它不会成为大数据的典型代表。Hadoop (或 Spark)应该嵌入在其他技术和产品中。这样一来,这些技术就可以利用 Hadoop (或 Spark)的强大功能,而不暴露其复杂性。
Hadoop 正如 TCP/IP 一样,问题是人们如何使用它。如果你想要从事大数据分析,那么请使用利用 Hadoop 功能的大数据分析软件。如果你这样做,Hadoop 将会复活,这不是靠魔法,而是靠常识。
作者:Andrew Brust
来源:中国大数据

未来的制造业要的不是石油,它最大的能源是数据.