学习数据分析,做大数据紧缺人才
浅谈数据分库分表之道
为什么讨论分库分表
在服务器后端技术人员的成长路线上,分片(Sharding)思想的理解和把握是绕不过去的门槛,而数据库分库分表可能是讲述拆分思想最好的教材,大部分后端技术人员都会在成长过程中遇到这样的问题。
为什么讲道,因为道比术重要一万倍。技术浪潮一波一波在推动社会的前进,新的技术雨后春笋,简单且朴实的道理,更长久也更朴实且普适。
分库分表是什么
我们如何描述分库分表。可以这样定义分库分表,当业务的增长导致数据库瓶颈的时候,一种解决瓶颈的手段。
数据库的是很容易出瓶颈的一个地方,瓶颈,包含性能,容量等等。一方面是存在放大效应。比如业务强要求所有的请求在100ms得到返回,这100ms分配到数据层,可能留的时间也就1-2ms,任何数据库的波动,会被放大10-20倍反应到上层。另一方面是存在单点问题,数据库保持了最新且最准确的状态,这个状态增长是随业务增长同步的,且业务的增长会导致业务的复杂性,复杂性最后反应到数据库的存储里代表的就是增量。数据库需要应对随业务增长指数上升的数据增量,且数据库系统本身通过单点性,来保持状态的准确性,很容易遇到单机的性能问题。
而分库分表就是大多数互联网公司遇到数据库瓶颈后,解决瓶颈的近乎行业标准手段。
分库分表的本质
我们回顾数据库发展的历史,数据库是怎么发展起来的,它在先解决什么问题,为什么现在会有瓶颈的问题
计算机的本质满足可计算性的快速计算。而数据库系统的本质来源于,随着计算力扩大随之匹配的对数据的储存和管理能力。最早的编程是通过在纸带上打孔来完成计算计算步骤的编写,输出的也是纸带。数据库就是对一系列纸带的管理,还别说,那时候就有搜索的需求了。

1968年,IBM做出了第一现代意义上的数据库系统。DBMS,除了没有SQL的支持,但是基本上已经是完善的现代数据库了。拥有现代数据库应有的,存储,检索,状态一致等功能。
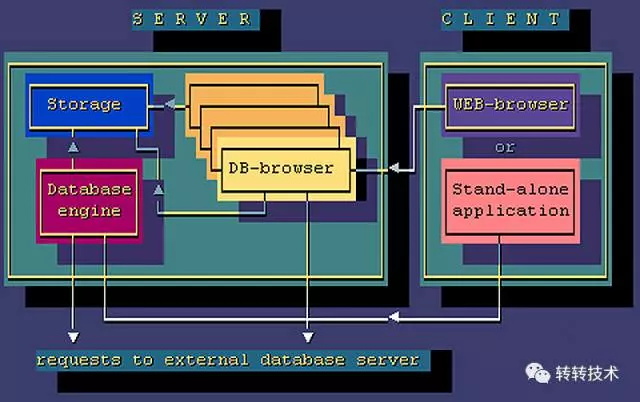
1970年后关系型数据库兴起,那时候搞关系型数据库的公司,就像现在专门做NoSQL的数据库那么的酷。Oracle 是关系型数据库最终的胜利者。如果去深挖这段历史,确实是IBM的员工在1974 年的时候提出了SQL的观点,但是在1979年,Oracle最终第一个做出了第一个关系型数据库。
这时候的数据库,和我们现在接触的数据库已经基本一致了。我们简单概括一下数据库所提供的功能。数据库系统有存储,管理,检索的需要。数据库对应提供了储存,索引,一致性的功能。数据库储存数据为文件,通过树的结构来提供索引,通过提供事务组的方式,来保证一致性。至于SQL,是用于管理数据的语言,用于扩展对数据的管理能力。
为什么现在会有数据库瓶颈的问题,在我看来就是,单机的到计算瓶颈了,计算的部分快速的转向分布式,大规模的集群。而数据库做集群的方式很难。对于单机应用来说,数据库基本上没有瓶颈,对于互联网公司来说,流量在不停的拆分,保证单台机器的处理负载在可处理范围内,但是因为数据库本身是一个针对单机的系统,同时需要保证一致性状态,所以更容易到瓶颈。数据库系统原本就是一个支持索引,一致性,和存储是一个相对平衡的单机应用,但是一旦想要扩展分布,那就要做一些权衡。
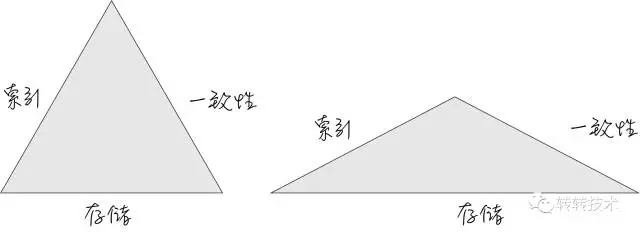
在我看来,分库分表就是拉伸存储,放弃一些,索引和一致性的一个方案。
如何拉伸储存
拉伸储存,本质上就是通过减少需要计算的数据量,来换取计算速度的这样一个过程。所以拆分的时候就是,如何计算速度最快那就如何拆分。所以贴子系统适合按日期分库分表,交易系统适合冷热数据分类,长期有效的商品系统,就需要按照Hash来直接水平拆分。
分表解决的是,过大的数据表影响计算速度的问题,比如单表上亿,那么我拆成十个表,那么我必然会比一个表更快,原因是,用了一部分计算落表时间,来换取表计算的时间。
分库更多解决的是机器的局限的问题,单机容量有限,单机容量实际上是由,机器硬件决定,比如我的网卡打满,CPU打满,机器磁盘写满,这种case,必须将计算分布到其他机器上解决。先拆分进程,随后将进程拆分到不同的机器上。
分库分表的核心是为了创建一个对业务相对透明的逻辑大表,隔离存储的负载度,进而实现在业务眼里的无限存储。
如何保障索引
一定要理解,索引和存储是相关隔离的两件事,而对于数据库来说,强行提升了储存,而索引就是需要付出的代价。
当存储分布之后,单机的索引是无法满足对索引的要求的,而SQL是对索引的更上一层的封装,这个部分会有一定程度的限制,比如,分库分表最多能满足两个维度的拆分,Join表这种操作就不要想了。
方法就是,简单索引逻辑靠中间件构建虚拟索引,复杂索引靠其他方式构建外置索引。
所有的分库分表的中间件的工作,无非是在数据源和应用之间封装一层虚拟的满足基本需要的索引。应用发送请求到中间件,中间件起到一部分索引的作用,判定需要到哪个库,哪个表来执行,这就是单机数据库,选择表过程的外置。中间件还有一个作用是,对涉及逻辑表的部分,进行一部分SQL逻辑改写,来最终判定到某些部分执行。
对于更复杂的查询要求,应用方需要单独构建另外的索引,即把索引单独拆出来做成一个系统,来满足检索需要。作为代价来说,外置的索引会比内置的索引相对慢些,这是在系统架构上需要注意的地方。但是作为大原则,尽量把需变计算逻辑放置在索引外进行。
如何保障一致性
分库分表还好的地方在于,数据最终存储是一份的,主从实际上是以主为准的,除了严格的时间外窗口外,对一致性存储的调整不是很大。但是因为分库分表把需要操作的数据源分散了,操作的原子性在保障起来是有损耗了,核心问题就在于,如何保障,跨数据库,跨进程,跨机器的操作原子性。
方法就是,外置保证一致性的方式。A,B,C 三个独立动作,想让他们保证一致,要么,在最前面一致,要么在最后面一致,就是消除这三个动作的中间状态。
通过MQ实现的数据一致性,相当于把动作归结为最终状态,用户付了款,那我就保证一定得完成支付,发券,等等相关动作,如果交易各种原因最终失败,我也得保证用户的这笔交易进入一个最终退款的状态。
通过软事务的方式来实现的最终一致性,方式就是外置检查,某一动作失败时,往前回滚,不一定完全回滚数据状态,但是属于是回滚到不影响发生其它业务逻辑的业务状态。比如下单,减库存,创建订单,创建订单失败,那我就需要释放库存,倒序回置状态。
一个分库设计实例
对于交易系统来说,天然区分冷热数据,交易核心订单一旦超过三个月之后,不太可能会再有更改问题,另外一个问题是,交易强事务驱动,必须依靠事务,对一致性强要求,交易的读写比实际上并不是特别的大。同时交易的访问量实际上相比于流量是有数据量级差异的,如果交易量打破单机瓶颈,有其他方式,与主题无关,不再详述。
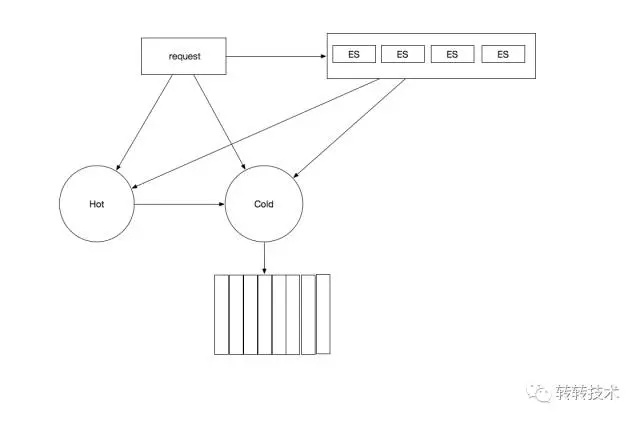
我们这套设计描述如下。交易维护一个热数据库,保留最近三个月的交易热数据,事务相关表尽量保留在这个数据库中,所有的交易的一致性需求必然会是热数据。冷库按时间分库,保留三个月之后的数据,随业务量扩展。在交易id拼入日期因素,中间件判定id是冷是热,确定查询方案,如果不好判定,先查询热库再查询冷库。两者之间靠MQ完成数据传输,保证交易数据不会丢失。线上业务一般无复杂查询,中间件可以搞定,对于线下业务,有相关复杂数据的,走单独构建的ES(搜索引擎)集群,来完成复杂检索。这样的设计基本可以满足相关交易需求。
总结
● 分库分表就是拉伸存储,放弃一些,索引和一致性的一个方案。
● 通过分库分表拉伸储存能力。
● 通过外置索引来解决复杂索引。
● 通过外置一致性来弥补操作一致性。
● 分库分表解决数据库远设计即为单点问题。
● 没有分库分表问题的公司不值得去,欢迎投递简历。
作者简介
汪涛,14年东北大学本科毕业。转转RD。
来源:转转技术

未来的制造业要的不是石油,它最大的能源是数据.