三位一体的工业大数据综述
工业大数据的目的是为了改变以往工业价值链从生产端向消费端、上游向下游推动的模式,实现以客户价值为核心的定制化产品和服务,以及与之相适应的全产业链协同优化。为此,工业大数据应满足用户需求定义、工业智能制造、活动协同优化三方面的应用。
在这些应用中,工业大数据的落地需要与之相适应的技术架构作为支撑。目前,李杰教授提出的“5C”架构体现了工业大数据“数据->知识->应用”的信息架构,而工业互联网参考架构(IIRA)和工业4.0参考架构(RAMI4.0)均是顶层系统架构,还有一些公司企业依据自身的业务提出了自定义的技术架构,如通用的Predix、三一的根云等。
我们知道技术架构应由应用场景的特征来决定,就现状而言,工业大数据还处在产业的初级阶段,对工业大数据应用场景的认知还不太深入,但大数据在互联网的应用已具备成熟的技术体系和应用框架,因此,本文主要通过比较工业应用场景和互联网应用场景的差异性,期望能够修正互联网大数据的相关应用技术框架,以满足工业大数据落地对技术框架的要求。
工业大数据和互联网大数据的技术架构都具备数据环境、知识环境和应用环境三个层,如下图所示。
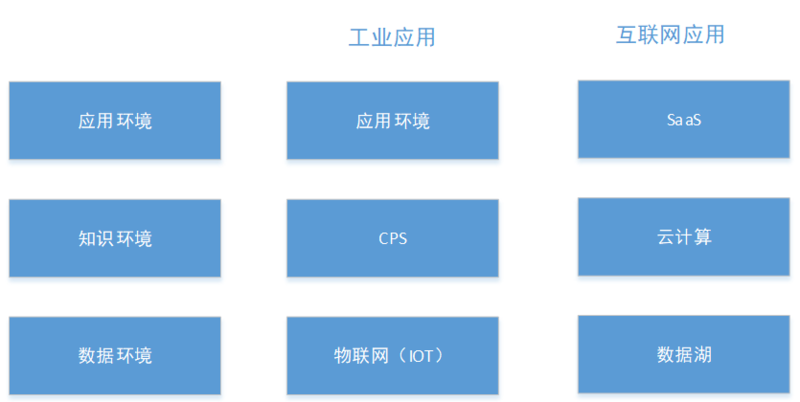
数据环境
从数据环境来看,首先,互联网大数据和工业大数据具备不同特征。如下表所示:
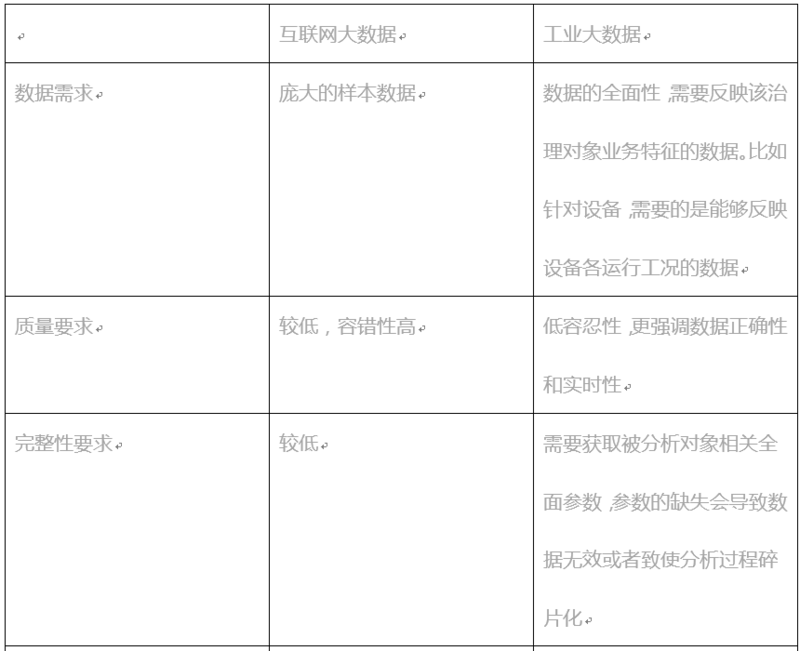
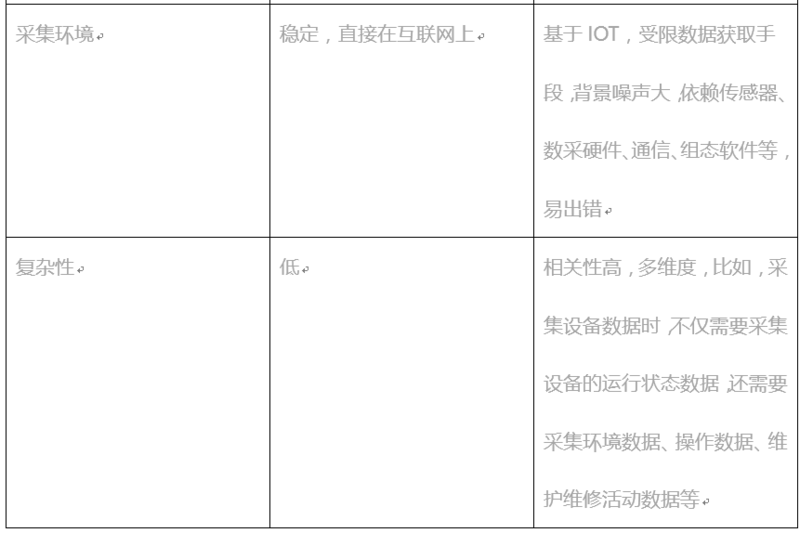

由于上述对数据的差异性,互联网大数据更多的是关注数据的持久化,其技术架构侧重于实现异构数据的存储、访问的一致性,满足多负载的并行读能力。所以,互联网催生了大量的非关系型数据库、实时数据库、分布式文件存储的技术。
工业大数据同样关注数据持久化,但工业大数据部署应用的一个原则是将应用尽可能部署在离数据产生源越近的地方。这是因为,就近部署其可靠性、实时性越高。需要按照业务需要进行部署,因此,很多应用部署在设备、生产车间等。所以,与互联网大数据集中式存放的方式相比,工业大数据对数据存放更加离散化,在空间中形成跨网的分布式存储,且各数据节点对数据存放、访问的能力要求不一样。比如以在某一公司实施的智能风场项目为例,在风机上部署的采集终端,需要存储结构化且要求实时性高的技术方案;在相应业务端,如生产系统或调度系统,数据是半结构化且实时性要求一般;在公司数据中心,数据是非结构化且需要语义组织。因此,需要抽象和设计一个统一的数据持久化环境,为工业大数据的上层应用提供基于语义的数据发现和相适宜的访问能力。
另外,工业大数据的数据环境,更关注数据采集的能力。工业大数据的数据采集依赖于物联网(IOT)的实现,IOT关注的采集的可靠性,实现数据接入的总线化,但工业大数据对IOT提出了更多的需要。以在某一公司实施的智能风场项目为例,在设计数据采集时,考虑了如下一系列的需要。
一,IOT终端需要具备边缘计算能力,首先是风机高频运行状态数据没必要全部上传,只需要上传从风机运行状态数据提取的相应特征数据,在必要时,如发生故障需要原始数据进行深入分析或者为训练模型需要原始数据,才需要终端上传数据。因此IOT终端需要运行特征提取算法;
二,IOT终端需要具备对采集数据的辨伪能力,需要对数据质量进行预判和修复。在采集风机运行数据时,数据大多是通过传感器,传感器本身存在故障、标定、存在寿命等问题,产生错误数据的概率较大,而坏数据对基于物理关联和因果分析的模型影响相对于互联网应用基于统计分析的影响更高;
三,IOT需要提供更智能的接入能力,形成数据生态环境,因为工业数据不会自发形成,不像互联网一样本身在线,需要解决传感器、物联网、嵌入式智能等在边缘端需要解决的技术问题;
四,IOT需要提供基于语义的定义,是因为作为工业大数据应用的最基本数据产生源,它是物理世界实体的高度抽象,能够映射物理世界实体的特征、实体间的关系,能够发现和被发现,提供互操作性,从而形成物理世界在虚拟世界里的组织和协作能力。
知识环境
工业大数据和互联网大数据都需要对数据进行分析、处理,以获得相应的知识,用以支撑上层业务应用。它们的差异性首先体现在模型特性上面。如下表所示:
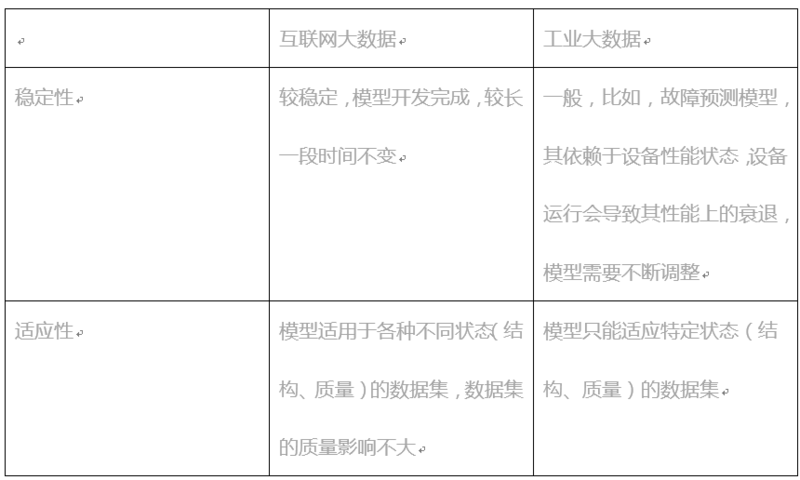
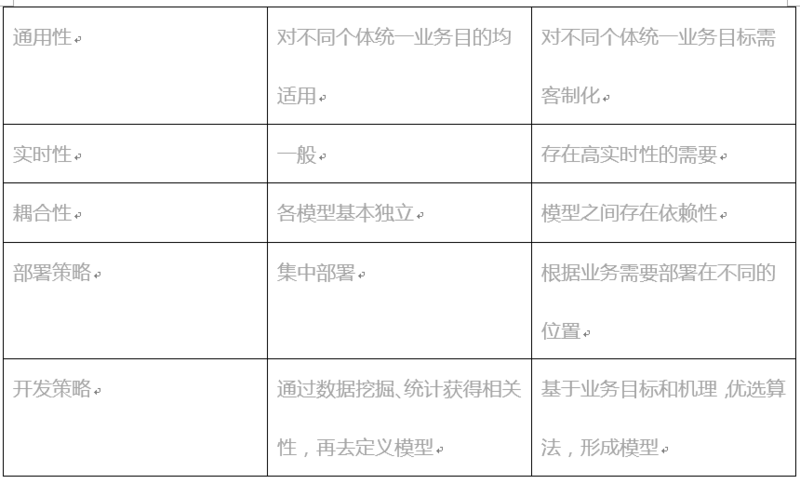
由模型的差异性,在工业大数据和互联网大数据应用中,对模型执行的环境要求有很大区别。
目前,在互联网环境中,一般都是基于云平台,使用hadoop生态环境进行搭建,通过流式或离线计算对数据进行处理,采用容器技术运行相应的计算模型,统一对外提供知识数据的访问,其根本是在于其服务或者算法的通用性和可复制性,当一个服务满足不了外部需求,可以通过容器方便的产生副本,扩展其提供外部访问的能力,而微服务、无服务等技术架构更多是基于对服务的结构、协作等的重新定义,来解决服务响应、资源使用、实施、并行等相关非功能特性。而在工业大数据中,绝大多数模型对外提供服务并不用在意访问的并发性,比如风场智能运维系统对某个风机的健康状态评估,使用其评估结果的外部访问仅限于几个终端,毕竟是只有与风机相关的干涉人才会需要。因此,工业大数据应用所需要的模型执行平台关注的是单例执行效率以及类型的扩展性。
另外,工业大数据应用的模型相关性较强。比如,在风场智能运维系统中,对风机的状态评估,依赖于对其组成的多个部件的健康评估,对风机发电效率预测需要结合环境、风机健康状态的结果。因此,工业大数据应用所需要的模型执行平台还需要提供较好的模型执行协作环境。
因此,工业大数据的知识环境的技术平台是CPS,云计算是CPS的一个组成部分。CPS关注的是物理实体映射的逻辑实体的管理,提供逻辑实体的关系、协作,以对称的方式来演进,体现与物理实体的相关性,实现知识的挖掘。
应用环境
互联网大数据的应用可以充分利用云平台相关的技术提供集中式的服务环境,对外以SaaS的方式提供应用功能,但工业大数据的应用多样,既有对物(设备、生产线)的嵌入式应用,也有与传统信息系统相似的应用,如风场的维护排程优化、设备状态监控,也有与互联网大数据应用相同的SaaS应用,如Predix。
因此,工业大数据的应用环境包括了嵌入式环境、单机环境、集群或云平台环境,需要考虑应用支撑环境的多样性统一;其次,工业大数据的应用部署可以在生产一线、控制中心、数据中心等地域分离的地方,其应用环境也需要提供应用跨域的协作能力和应用从故障中恢复的能力;工业大数据的应用环境不仅需要提供服务本身的弹性扩展(并发能力和瞬时负载能力),还需要提供服务的(类型、行为、资源要求)多样性扩展。
总之,由互联网推动的大数据、智能应用等已成熟的技术体系和应用框架,是构建工业大数据应用的最好参考,是工业大数据技术实施的基础。但建立有效的工业大数据应用,离不开工业应用技术的核心——CPS平台,并在相应的信息架构、资源架构等方面,做出合适的设计和实践。
作者:朱武
来源:网络大数据

未来的制造业要的不是石油,它最大的能源是数据.