深度学习应该使用复数吗?
深度学习只能使用实数,大家不觉得奇怪吗?或许,深度学习使用复数才是更加奇怪的事情吧(注意:复数是有虚部的)。一个有价值的论点是:大脑在计算的时候不太可能使用复数。当然你也可以提出这样的论点:大脑也不用矩阵运算或者链式法则微分啊。此外,人工神经网络(ANN)具有实际神经元的模型。长期以来,我们用实分析代替了生物合理性(biological plausibility)。
然而,为什么我们要止步于实分析呢?我们已经用了这么久线性代数和微分方程,那我们也可以将这一切都推倒,用复分析建立新的一套。或许更加奇妙的复分析会赋予我们更强大的方法。毕竟它对量子力学奏效,那么它也有可能在深度学习领域发挥作用。此外,深度学习和量子力学都与信息处理有关,二者可能是同一件事情。
由于论据的原因,我们暂且不考虑生物合理性。这是一个很古老的观点,可以追溯到 1957 年 Frank Rosenblatt 第一次提出人工神经网络的时候。那么问题来了,复数可以提供哪些实数不能提供的东西呢?
在过去几年里,曾经出现过一些探索在深度学习中使用复数的文章。奇怪的是,它们中的大部分都没有被同行评议的期刊接受。因为深度学习的正统观念在该领域已经很流行了。但是,我们还是要评述一些有趣的论文。
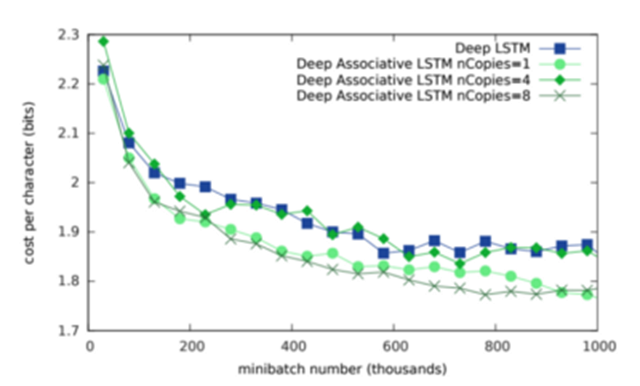
DeepMind 的论文《Associative Long Short-Term Memory》(Ivo Danihelka, Greg Wayne, Benigno Uria, Nal Kalchbrenner, Alex Graves)探讨了使用复数值形成联想记忆神经网络。该系统被用来增强 LSTM 的记忆。论文的结论是使用复数的网络可获取更大的记忆容量。根据数学原理,与仅仅使用实数的情况相比,使用复数需要的矩阵更小。如下图所示,使用复数的神经网络在内存开销上与传统 LSTM 有显著区别。
Yoshua Bengio 及其在蒙特利尔的团队探索了另一种使用复数的方式。研究者在《Unitary Evolution Recurrent Neural Networks》(Martin Arjovsky, Amar Shah, Yoshua Bengio)一文中探讨了酉矩阵。他们认为,如果矩阵的特征值接近 1 的话,消失的梯度或许会带来实际的好处。该研究使用复数作为 RNN 网络的权重。结论如下:
实证表明我们的 uRNN 能够更好地通过长序列传递梯度信息,并且不会遇到像 LSTM 一样多的饱和隐藏状态(saturating hidden states)。
他们做了多次实验对使用复数的网络与传统 RNN 的性能进行了量化比较:

使用复数的系统明显拥有更鲁棒、更稳定的性能。
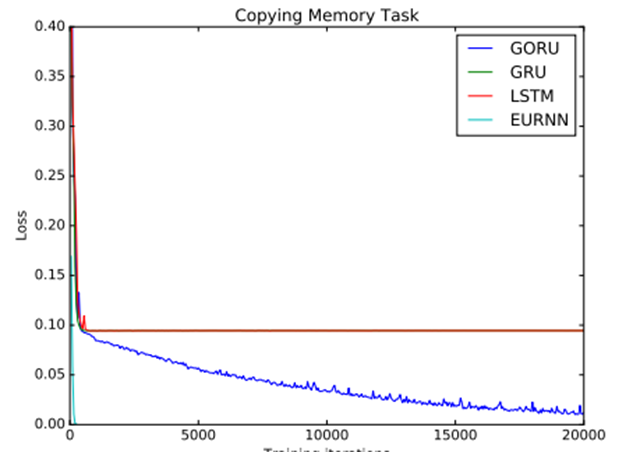
Bengio 团队和 MIT 合作的一篇论文《Gated Orthogonal Recurrent Units: On Learning to Forget》(Li Jing, Caglar Gulcehre, John Peurifoy, Yichen Shen, Max Tegmark, Marin Solja?i?, Yoshua Bengio)提出了使用门控机制的方法。这篇论文探讨了长期依赖能够更好地被捕获以及形成一个更加鲁棒的遗忘机制的可能性。下图展示了其他基于 RNN 的系统在复制任务中的失败;
FAIR 和 EPFL 的一个团队出了一篇类似的论文《Kronecker Recurrent Units》(Cijo Jose, Moustpaha Cisse, Francois Fleuret),他们在论文里也展现了在复制任务中使用酉矩阵的可行性。他们展示了一种能够大幅减少所需参数的矩阵分解方法。文中描述了他们使用复数的动机。
由于实空间的行列式是连续函数,所以实空间的酉集是不连贯的。因而,使用标准的连续优化程序不能在实值网络上跨越全酉集。相反,酉集在复空间中是连接在一起的,因为它的行列式是复空间中单位圆上的点,所以使用复数就不会出现这个问题。
这篇论文的精华之一就是下面这则富有建设性的思想:
状态应当保持高维度,以使用高容量的网络将输入编码成内部状态、提取预测值。但 recurrent dynamic 可使用低容量模型实现。
目前,这些方法已经探索了在 RNN 上对复数值的使用。MILA(蒙特利尔学习算法研究所)最近的一篇论文《Deep Complex Networks》(Chiheb Trabelsi 等人)进一步探索了这些方法在卷积神经网络上的使用。论文作者在计算机视觉任务上测试了他们的网络,结果很有竞争力。
最后,我们必须说一下复数在 GAN 中的使用。毕竟 GAN 可以说是最热的话题了。论文《Numerics of GANs》(Lars Mescheder, Sebastian Nowozin, Andreas Geiger)探讨了 GAN 中棘手的收敛性能。他们研究了带有复数值的雅克比矩阵的特点,并使用它创建解决 GAN 均衡问题的最先进方法。
在去年的一篇博文中,我介绍了全息原理和深度学习的关系。博文中的方法探索了张量网络和深度学习架构网络之间的相似性。量子力学可以被认为是使用了一种更加通用的概率形式。对复数的使用则提供了常规概率无法提供的额外能力。具体来说就是叠加和干扰的能力。为了实现全息术,在处理过程中使用复数会比较好。
在机器和深度学习空间中进行的大多数数学分析倾向于使用贝叶斯思想作为参数。事实上,大多数从业者都认为它是贝叶斯的,但实际上来自与统计学机制(除去名字,这里没有统计学的那些繁文缛节)。
但如果量子力学是广义的概率,那如果我们使用 QM 启发的方法作为替代会如何呢?一些论文试图研究这一方向,结果值得一看。在去年的一篇论文《Quantum Clustering and Gaussian Mixtures》中,作者探索了无监督均值聚类的使用情况。报告是这样说的:
因此,我们观察到了量子类干扰现象并不在高斯混合模型中出现。我们展示了量子方法在所有方面上都优于高斯混合方法。
两者的对比如图:

噪声发生了什么?
为什么在有了 20 实际的量子概率理论后还要拘泥于 18 世纪的贝叶斯理论呢?
本文提及的研究论文证明了:在深度学习架构中使用复数确实会带来「实实在在」的优势。研究表明:使用复数能够带来更鲁棒的层间梯度信息传播、更高的记忆容量、更准确的遗忘行为、大幅降低的网络规模,以及训练 GAN 时更好的稳定性。这些优点可不能被简单地忽略。如果我们接受了目前深度学习的主流观点–任何一层的微分都是公平的,那么或许我们应该在存储很多变体的网络中使用复分析。
或许复数没有被经常使用的原因是研究者对它不够熟悉。在优化研究社区中,数学传统并没有涉及到复数。然而物理学家却一直在使用复数。那些虚部在量子力学中始终是存在的。这并不奇怪,这就是现实。我们仍然不太理解为何这些深度学习系统会如此有用。所以探索其他的表示可能会带来出乎意料的突破。
在不久的将来,这个局面可能会变化。最先进的结构可能会普遍使用复数,那时候不使用复数反倒变得奇怪了。
来源:36大数据

未来的制造业要的不是石油,它最大的能源是数据.