每个人都应该知道的3种机器学习算法
作者:Eleni Markou
假设有一些跟数据相关的难题需要你去解决。之前你已经听过机器学习算法的厉害之处了,因此你自己也想借此机会尝试一番——但是你在这个领域并没有经验或知识。于是你开始用谷歌搜索一些术语,比如“机器学习模型”和“机器学习方法”,但一段时间后,你发现自己在不同算法之间已经完全迷失了,所以便开始放弃了。
坚持才能胜利!
幸运的是,我将在本文介绍三个主要的机器学习算法,了解了这些内容后,我相信针对于大多数的数据科学难题,你都可以满怀自信去解决。
在下面的文章中,我们将讨论决策树、聚类算法和回归,指出它们之间的差异,并找出如何根据不同的案例选择最合适的模型。
有监督学习 VS 无监督学习
理解机器学习的基础就是如何对有监督学习和无监督学习这两个大类进行分类的问题,因为机器学习问题中的任何一个问题最终都是这两个大类中的某一个。
在有监督学习的情况下,我们有数据集,某些算法会将这些数据集作为输入。前提是我们已经知道正确的输出格式应该是什么样子(假设输入和输出之间存在某种关系)。
稍后我们看到的回归和分类问题都是属于这一类。
另一方面,无监督学习适用于我们不确定或者不知道正确的输出应该是什么样子的情况。事实上,我们需要根据数据推导出正确的结构应该是什么样。聚类问题是该类的主要代表。
为了使上述分类更加清晰,我将列举一些现实世界的问题,并尝试对它们进行相应的分类。
实例1
假设你在经营一家房地产公司。考虑到新房子的特点,你想基于之前记录的其他房子的销售情况,从而预测这间房屋的销售价格应该在什么价位。输入的数据集包含多个房子的特征,比如浴室的数量和大小,而你想要预测的变量,通常称为目标变量,在本例子中也就是价格。因为已经知道了数据集中房子的出售价格,因此这是一个有监督学习的问题,说的更具体一点,这是一个关于回归的问题。
实例2
假设你做了一项实验,根据某些物理测量结果以及遗传因素,来推断某人是否会发展成为近视眼。在这种情况下,输入的数据集是由人体医学特征组成的,目标变量是双重的:1表示那些可能发展近视的人,0表示没有成为近视眼的人。由于已经提前知道了参与实验者的目标变量的值(即你已经知道如果他们是否是近视),这又是一个有监督学习的问题——更具体地说,这是一个分类的问题。
实例3
假设你负责的公司有很多的客户。根据他们最近与公司的互动结果,最近购买的产品,以及他们的人口统计资料,你想要把相似的客户组成一个群体,以不同的方式来对待他们——比如给他们提供独家折扣券。在这种情况下,将会使用上面提到的某些特性作为算法的输入,而算法将决定应该客户群的数量或类型。这是无监督学习最典型的一个例子,因为我们事先根本就不知道输出结果应该是怎样的。
话虽如此,现在是实现我的承诺的时候了,来介绍一些更具体的算法……
回归
首先,回归不是单一的有监督学习的技术,而是许多技术所属的整个类别。
回归的主要思想是给定一些输入变量,我们想要预测目标变量的值是什么样的。在回归的情况下,目标变量是连续的——这意味着它可以在指定范围内取任意的值。另一方面,输入变量既可以是离散的,也可以是连续的。
在回归技术中,最广为人知的就是线性回归和逻辑回归了。让我们仔细研究研究。
线性回归
在线性回归中,我们试图建立输入变量与目标变量之间的关系,这种关系是由一条直线表示的,通常称为回归线。
例如,假设我们有两个输入变量X1和X2以及一个目标变量Y,这种关系可以用数学形式表示:
Y = a * X1 + b*X2 +c
假设已经提供了X1和X2的值,我们的目标是对a、b、c三个参数进行调整,从而使Y尽可能接近实际值。
花点时间讲个例子吧!
假设我们已经有了Iris数据集,它已经包含了不同类型的花朵的萼片和花瓣的大小数据,例如:Setosa,Versicolor和Virginica。
使用R软件,假设已经提供了花瓣的宽度和长度,我们需要实现一个线性回归来预测萼片的长度。
在数学上,我们将通过如下关系是获取a、b的值:
SepalLength = a * PetalWidth + b* PetalLength +c
相应的代码如下:
# Load required packages
library(ggplot2)
# Load iris dataset
data(iris)
# Have a look at the first 10 observations of the dataset
head(iris)
# Fit the regression line
fitted_model <- lm(Sepal.Length ~ Petal.Width + Petal.Length, data = iris)
# Get details about the parameters of the selected model
summary(fitted_model)
# Plot the data points along with the regression line
ggplot(iris, aes(x = Petal.Width, y = Petal.Length, color = Species)) +
geom_point(alpha = 6/10) +
stat_smooth(method = "lm", fill="blue", colour="grey50", size=0.5, alpha = 0.1)
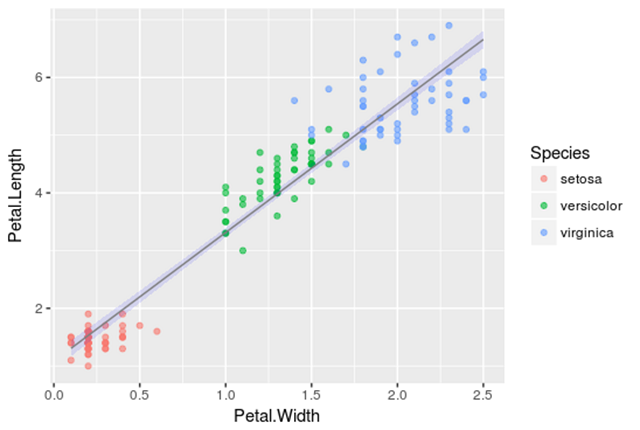
线性回归的结果如下图所示,黑点表示初始数据点在蓝线拟合回归直线,于是便有了估算结果,a= -0.31955,b = 0.54178,和c = 4.19058,这个结果可能最接近实际情况,即花萼的长度。
从现在开始,通过将花瓣长度和花瓣宽度的值应用到定义的线性关系中来,新出现的数据点我们也可以预测它的长度了。
逻辑回归
这里的主要思想和线性回归完全一样。最大的不同就是回归线不再是直的的。
相反,我们试图建立的数学关系是类似于以下形式:
Y=g(a*X1+b*X2)
这里的g()就是逻辑函数。
由于logistic函数的性质,Y是连续的,在[0,1]范围内,可以理解为事件发生的概率。
我知道你喜欢例子,所以我再给你看一个!
这次,我们将对mtcars数据集进行实验,该数据集包括燃料消耗和汽车设计的10个方面,以及1973 – 1974年生产的32辆汽车的性能。
使用R,我们将根据V/S和Miles/(US)加仑的测量值,预测自动变速器(am = 0)或手动(am = 1)汽车的概率。
am = g(a * mpg + b* vs +c):
# Load required packages library(ggplot2) # Load data data(mtcars) # Keep a subset of the data features that includes on the measurement we are interested in cars <- subset(mtcars, select=c(mpg, am, vs)) # Fit the logistic regression line fitted_model <- glm(am ~ mpg+vs, data=cars, family=binomial(link="logit")) # Plot the results ggplot(cars, aes(x=mpg, y=vs, colour = am)) + geom_point(alpha = 6/10) + stat_smooth(method="glm",fill="blue", colour="grey50", size=0.5, alpha = 0.1, method.args=list(family="binomial"))
结果如下图所示,其中黑点代表数据集的初始点,蓝色线代表a = 0.5359,b = – 2.7957,c = – 9.9183的拟合逻辑回归线。
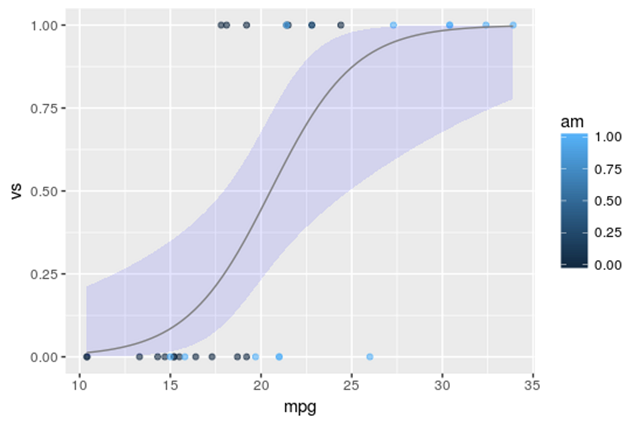
正如前面所提到的,我们可以观察到由于回归线的形式,logistic回归输出值只在范围[0,1]中。
对于任何以V/S和Miles/(US)加仑为标准的新车,我们现在可以预测这辆车自动变速器的概率。
决策树
决策树是我们将要研究的第二种机器学习算法。决策树最终分裂成了回归和分类树,因此可以用于有监督学习问题。
诚然,决策树是最直观的算法之一,它们可以模仿人们在大多数情况下的决定方式。他们所做的基本上就是绘制出所有可能路径的“地图”,并在每种情况下画出相应的结果。
图形表示将有助于更好地理解我们正在讨论的内容。
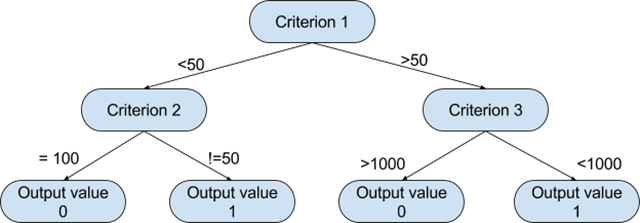
基于这样一棵树,算法可以根据相应的标准值决定在每个步骤中遵循哪条路径。算法选择分割标准的方式和每个级别的相应阈值,取决于候选变量对目标变量的信息量,以及哪个设置最小化了所产生的预测错误。
这里还有一个例子!
这一次讨论的数据集是readingSkills。它包括了学生的考试成绩和分数。
我们将基于多种指标把学生分为母语为英语的人(nativeSpeaker = 1)或外国人(nativeSpeaker = 0),包括他们在测试中的得分,他们的鞋码,以及他们的年龄。
对于R中的实现,我们首先需要安装party包。
# Include required packages library(party) library(partykit) # Have a look at the first ten observations of the dataset print(head(readingSkills)) input.dat <- readingSkills[c(1:105),] # Grow the decision tree output.tree <- ctree( nativeSpeaker ~ age + shoeSize + score, data = input.dat) # Plot the results plot(as.simpleparty(output.tree))
我们可以看到,使用的第一个分裂标准是分数,因为它在预测目标变量时非常重要,而鞋子的大小并没有被考虑在内,因为它没有提供任何关于语言的有用信息。
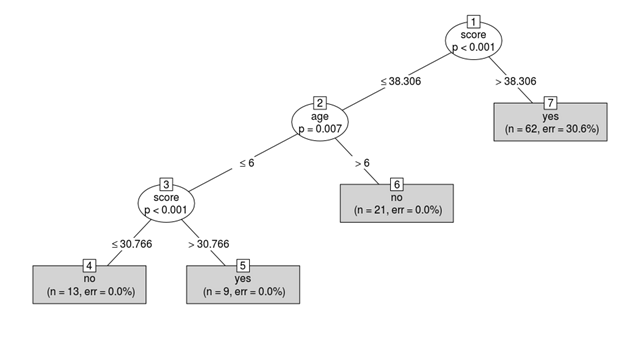
现在,如果我们有了一个新学生,知道他们的年龄和分数,我们就可以预测他们是不是一个以英语为母语的人!
聚类算法
到目前为止,我们只讨论了一些关于有监督学习的问题。现在,我们继续研究聚类算法,而它则是无监督学习方法的子集。
所以,只是稍微修改了一点…
对于集群,如果有一些初始数据进行支配,我们想要形成一个组,这样一些组的数据点是相似的,并且不同于其他组的数据点。
我们将要学习的算法叫做k-means,k表示产生的簇的数量,这是最流行的聚类方法之一。
还记得我们之前用过的Iris数据集吗?我们将再次使用它。
为了研究,我们用他们的花瓣测量方法绘制了数据集的所有数据点,如下图所示:
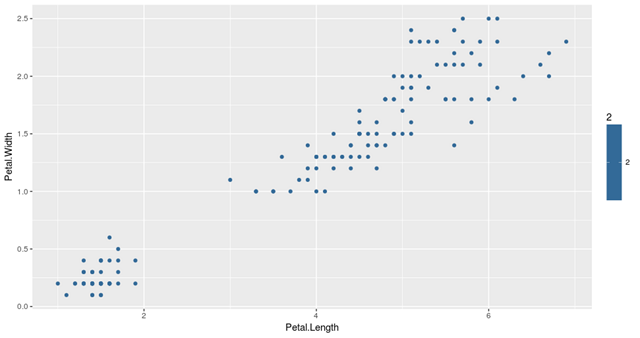
基于花瓣的度量值,我们将使用3-means clustering方法将数据点聚集成3组。
那么3-means,或者说是k-means算法是如何工作的呢?整个过程可以用几个简单的步骤来概括:
- 初始化步骤:对于k = 3簇,算法随机选取3个点作为每个集群的中心点。
- 集群分配步骤:算法通过其余的数据点,并将每个数据点分配给最近的集群。
- Centroid移动步骤:在集群分配之后,每个集群的中心点移动到属于集群的所有点的平均值。
步骤2和步骤3重复多次,直到对集群分配没有更改。R中k-means算法的实现很简单,可以用以下代码实现:
# Load required packages library(ggplot2) library(datasets) # Load data data(iris) # Set seed to make results reproducible set.seed(20) # Implement k-means with 3 clusters iris_cl <- kmeans(iris[, 3:4], 3, nstart = 20) iris_cl$cluster <- as.factor(iris_cl$cluster) # Plot points colored by predicted cluster ggplot(iris, aes(Petal.Length, Petal.Width, color = iris_cl$cluster)) + geom_point()
从结果中可以看出,该算法将数据分成三组,分别用三种不同的颜色表示。我们也可以观察到这些簇是根据花瓣的大小形成的。更具体地说,红色表示花瓣小的花,绿色表示花瓣相对较大的蝴蝶花,而蓝色则表示中等大小的花瓣。
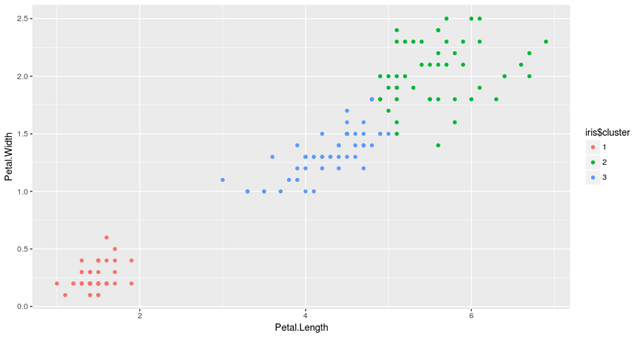
值得注意的是,在任何聚类中,对形成群体的解释都需要在该领域有一些专家知识。在我们的例子中,如果你不是一个植物学家,你可能不会意识到k – means所做的是把iris聚集到他们不同的类型,例如Setosa,Versicolor和Virginica,而没有任何关于它们的知识!
因此,如果我们再次绘制数据,这个时间被它们的物种着色,我们将看到集群中的相似性。
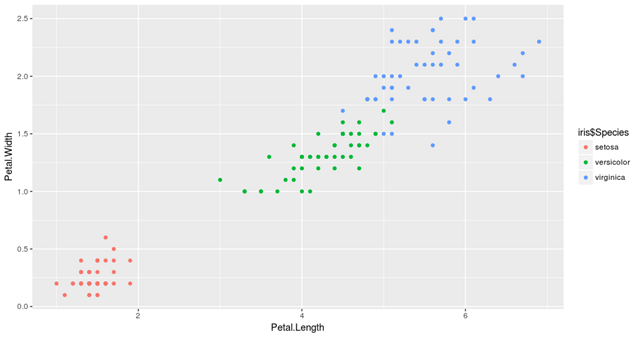
总结
我们从一开始就走了很长一段路。我们讨论了回归(线性和逻辑)和决策树,最后讨论了k – means集群。我们还在R中实现了一些简单但强大的方法。
那么,每种算法的优点是什么呢?在现实生活中,你应该选择哪一个?
首先,所呈现的方法并不是一些不适用的算法——它们在世界各地的生产系统中被广泛使用,因此需要根据不同的任务进行选择,选择恰当的话可以变得相当强大。
其次,为了回答上述问题,你必须清楚你所说的优点究竟是什么意思,因为每种方法在不同环境中展现出来的优点是不同的,例如解释性、稳健性、计算时间等。
现在,我们终于可以自信地将这些知识应用于一些实际的问题了!
End.
来自:36大数据

未来的制造业要的不是石油,它最大的能源是数据.