大数据:数据科学家应该拥有的好习惯
数据分析的好习惯
1. 分析大数据前,一定要尽可能多的进行数据可视化!可视化!可视化!做exploratory data analysis
我上过的几乎所有的应用性的统计课程上的老师都会强调这一点。这个习惯对于数据科学家、统计学家来说估计是最最实用的。
在实际的数据分析过程中,数据可视化可以揭示很多insights:从选择什么样的模型,选择哪些feature建模,到如何分析结果,解释结果等等。
给一个很著名的例子, Anscombe's quartet (安斯库姆四重奏):这个例子包含四组数据。每组数据有11个(x, y)数据样本点。
四组数据样本里x的均值方差全相等,y的均值方差基本相等,x与y的相关系数也很接近。
导致的结果是,四组大数据线性回归的结果基本一样。但是,这四组大数据本身差别很大。如下图。
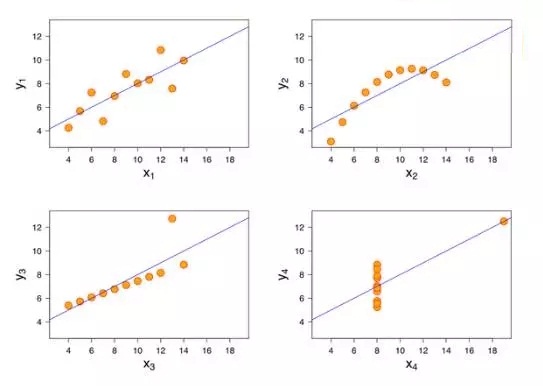
如果不做数据可视化,简单跑一个线性回归,我们只能得到同样的回归线。
数据可视化后,很直观的,左上图是传统的线性回归;右上图需要high-order nonlinear term;左下图x和y是线性关系,但是有outlier;右下图x和y没有线性关系,也有outlier, etc.
每一个数据科学家都应该熟悉各种图的画法,更重要的是,不同的图如何反映不同的信息以及面对不同的大数据类型时,应该选择哪种图才能最好的揭示大数据里蕴含的信息。
为此,强烈推荐关于R里ggplot包的教程:ggplot2 - Elegant Graphics for Data Analysis
当然另一方面,如果大数据量太大维度太高,数据可视化做起来就比较困难。这时候就需要一些经验技巧了。
2. 跑完程序得到模型结果时,一定提醒自己:任务只完成50%,分析,验证,解释结果才是根本
很多时候,我们以为写完code跑完程序就完事了。能做到这一步只能算是一个合格的data analyst。这离数据科学家,统计学家还差远了。
分析,验证,解释结果才是根本! 这个过程更需要data sense, domain knowledge, and statistical expertise.
在拿到结果的时候,一定要多问自己为什么。
模型assumptions是否满足?结果是否make sense?能否解答research question?
特别当结果不符合expectation时,要么有新发现,要么有错误!如果有错,错在哪里?
如果模型假设不成立,如何修正?是否有outliers,如何处理?
或有missing values,missing的机制是啥样的(missing at random, completely at random, or NOT at random)?
是否有multicollinearity?
大数据收集是否有bias (如selection bias)?
建模是否忽略了confounding factors (Simpson's paradox)?
3. 养成story-telling的习惯
把分析大数据结果跟你的boss或者collaborator讲!务必让他们明白!这个太需要技巧了, 特别是当你的collaborator是layperson的时候。
不会说只能等着被虐,哪怕analysis做的再好!
数据科学的好习惯
1、永远不要轻信自己的分析结果,多用业务和常识去检验
很多时候,我们的分析都是含有一些潜在的假设,而在分析过程中被忽略。比如最经典的案例是在1948年,盖洛普错误地预测了杜威能击败杜鲁门而当选总统。
原因是多方面的,但是抽样中的潜在不平均是不可否认的!再比如有个人分析结果得到刚毕业的专科的平均薪资比同专业的本科要高,就找一堆理由来说明这个结论。
但是领导说这个不符合常识,打回去重新分析。之后发现是因为样本男女比例不均衡导致的。
所以,我们不要轻信自己的数据分析结果,尤其是不能给自己的大数据分析找正向的理由!
因为只有你找理由,总会能给自己的结论找到一堆理由。有多从实际出发,如果不符合常识,那就更要多方面论证,才能发声!否则,就会是个笑话!
2、阅读人文:大数据科学不仅是一门科学,也是一门艺术
大数据科学,你可以认为是一门探索人性的科学。
我经常跟周围做数据或者IT人的说的一点是,因为我们是做数据或者写一些代码的,这里的数字是1就是1,不会是2,TRUE了就不会是FALSE,所以做久了,人容易偏执,不会享受生活,那就无法把艺术引进!
这里也举一个例子,美国有一家大型商场,业务经理想能否预测一个客户是否是孕妇,以此来针对性的营销呢?
他们的数据科学家通过分析找到了一个模型来预测。那么他们是直接把孕妇相关产品推荐给客户吗?
不是的,因为这个数据科学家不仅是数学好还是一个社会学家,他说如果全部推荐相关产品,那么客户会觉得自己的隐私被侵犯,甚至会觉得反感,所以他的策略是把真正想要推荐的东西放在一堆其他东西里。
当然,这里只是简写,实际过程非常有趣。
3、了解行业信息和业务信息
这一点非常重要。分析和挖掘,最终都是要落到具体的业务上来的。所以做大数据,不能脱离业务和行业规律。了解行业信息,能够让你在分析的时候更加的接地气、更好的把握分析框架!尤其是,联系刚才说的第一点,你积累的行业信息和业务信息都会帮助你检验你的分析,同时让你更还的认识到什么样的分析是有价值的分析。
对于业务中的乱七八糟的各种概念更是要深入理解,不能停留在表面。有时候,一个业务概念理解失误(比如0是否有参与计算),会导致大数据分析出完全相反的结论。
据说,数据分析会导致经验累积加速,简单的说一般业务人员工作10年的工作经验,数据分析5年就能掌握。
4、好奇心与多沟通
爱因斯坦说过,提出一个好问题比找到一个合适的答案更重要!
在我个人经验中,按照既定的一些分析框架分析,一般都只是完成了既定的任务而已。但是,你对分析中的一些异常多问几个为什么,很容易找到一些业务的突破口。
比如你分析销售业绩,你发现一个人,成单比例总是比别人高,甚至有时候比特别有经验的人还高,你就问问为什么呢?否则,你就只能发现这个数字而已。
后来,你通过分析和直接询问等方法,发现他发现了新注册的用户容易成单,所以每天盯着新用户呢!
当然,这样的例子是比较多的,比如为什么要让用户自己选择一些信息呢?然后一个大数据产品就出来了。
5、多实践与多走一步
这里涉及到模型了,也是我个人做的比较多的地方。
在数值计算(或者任何其他工程领域)里,知道一个东西的基本算法和写出一个能在实际中工作得很好的程序之间还是有一段不小的距离的。
有很多可能看似无关紧要的小细节小 trick,可能会对结果带来很大的不同。
当然这样的现象其实也很合理:因为理论上的工作之所以漂亮正是因为抓住了事物的主要矛盾,忽略“无关”的细节进行了简化和抽象,从而对比较“干净”的对象进行操作,在一系列的“assumption”下建立起理论体系。
但是当要将理论应用到实践中的时候,又得将这些之前被忽略掉了的细节全部加回去,得到一团乱糟糟,在一系列的“assumption”都不再严格满足的条件下找出会出现哪些问题并通过一些所谓的“engineering trick”来让原来的理论能“大致地”继续有效。
这些东西大概就主要是 Engineer 们所需要处理的事情了吧?这样说来 Engineer 其实也相当不容易。这样的话其实 Engineer 和 Scientist 的界线就又模糊了,就是工作在不同的抽象程度下的区别的样子。
在工作和平时学习练习中,都是这样。很多人问的太多,做的太少,导致眼高手低。比如你问用Ensemble,会怎么怎么样呢?对哇,很多人能问这个问题,但是就是不去试一试。
再比如,有偏样本的问题,有过抽样、欠抽样、阈值调整等等方法,都可以去自己实践一下,才会有更加直观的认识,否则只停留在讨论阶段是没用的。多走一步,每个问题都是自己成长的阶梯。
对于其他的,比如责任心、细心啥的,这些是其他职业也要求的,而专业性,这个就更不用说了。
End.
未来的制造业要的不是石油,它最大的能源是数据.