学习数据分析,做大数据紧缺人才
【干货】清华陆薇:释放工业大数据价值
本文讲稿和PPT由陆薇博士和主办方授权获得,大数据文摘(bigdatadigest)和数据派(datapi)联合发布。速记内容有删改,转载具体要求见文末。

导读:第四次工业革命以美国的工业互联网、德国的工业4.0为代表。中国也提出了“中国制造2025”的发展纲要。大数据对于工业、制造业的价值又在哪里呢?在首届中国大数据应用大会上,清华大学数据科学研究院·工业大数据研究中心的常务副主任陆薇所了题为《释放工业大数据价值》的演讲。原文如下:



首先,简单介绍一下清华大学数据科学研究院工业大数据研究中心。清华大学数据科学研究院成立于2014年春,结合了清华在信息技术,特别是分布式系统和数据管理分析技术方面的优势,以及工科、经济、人文、健康等各大数据应用领域的深厚积淀,致力于发挥学科交叉的协同作用,推进大数据系统研究与应用实践,培养人才,同时也参与贡献大数据相关国家战略。
突破工业大数据核心技术
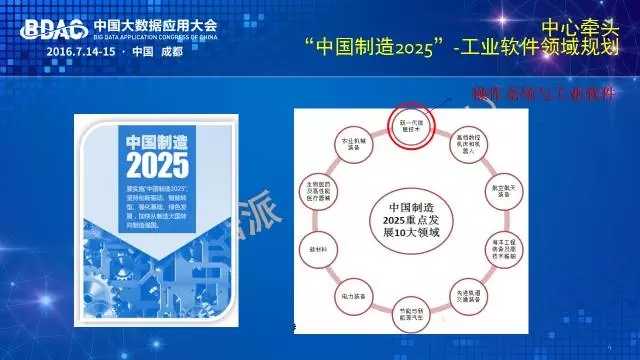
2014年到2015年,中心在工程院、工信部的领导下牵头制定了“中国制造2025”操作系统与工业软件方面的规划,定义了嵌入式工业操作系统、工业大数据平台和协同制造工业云三个发展方向。其中工业大数据也被选为“中国制造2025”的重点专题之一。中心目前正进一步推进工业大数据路线图落地实施和行业示范。

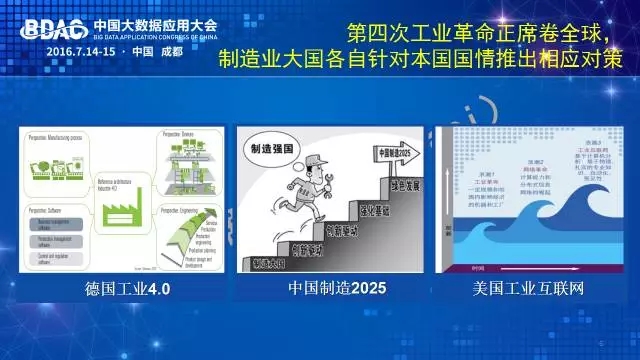
众所周知,第四次工业革命以美国的工业互联网、德国的工业4.0为代表,根据各国制造业不同的发展优势而各具特点。美国制造业大量外包生产环节,比如波音公司的飞机部件是在全球多个国家制造,但是美国制造企业牢牢占据高知识产权和附加值的产品设计和服务环节,同时把控整个生态链的上下游为其服务。因此,美国提出的工业互联网的智能核心在云不在端,关注利用互联网技术的资源优化配置作用提升对整个产业生态链的效率和价值。德国的情况则正相反,德国制造业优势在于实体制造,有精良的生产设备和工艺手段。因此,德国提出的工业4.0重点在于智能工厂本身的建设,并以制造为核心,带动上下游业务发展。
我国工业具有自己的特点。一方面,我国是世界工厂,实体制造比重大,同时低水平、劳动密集、高资源消耗制造的比重也大,产业升级迫在眉睫。另一方面,我国互联网产业发展具有领先优势。过去十多年消费互联网的高速发展使互联网技术得到长足发展,互联网思维深入人心。我们需要充分发挥这一优势,并将之和制造业紧密结合,促进制造业升级和生产性服务业的发展。
因此,我国制订的“中国制造2025”战略从我国实际国情和发展需求出发,兼顾智能制造和制造服务,用互联网技术驱动制造全生命周期从设计、制造到交付、流通、服务、回收各个环节的数字化、互联化、智能化升级,推动制造全产业链智能协同,优化生产要素配置和资源利用,消弭低效中间环节,从而整体提升中国制造业发展水平和世界竞争力。

虽然发展重点各有侧重,但大数据被公认为是不可或缺的关键技术。
德国的《工业4.0十大挑战与机遇》报告指出,数据的整合分析与使用是实现工业4.0的关键能力。工业4.0有两大关键支撑技术。一个是CPS,这是智能工厂比较偏硬的部分,讲究用更加智能的基础设施来降低车间复杂度和提高灵活性。另一个是数字化企业平台,跨生产”shop floor”和经营“top floor”、贯穿CAD/PLM/MES/ERP等生产、经营信息系统的信息集成与数据融合贯通,建立伴随产品制造过程的完整信息流,做到全数字化、数据全采集、数据通路全打通、数据流动过程不落地。同时基于对这些数据的分析,使企业可以全面深入把握和优化提升产品质量、生产效率、资源利用率。
美国通用电气公司的《工业互联网白皮书》中指出工业互联网实现的三大要素是智能联网的机器、人与机器协同工作及先进的数据分析能力。工业互联网的核心是通过智能联网的机器感知机器本身状况、周边环境以及用户操作行为,并通过这些数据的深入分析来提供诸如资产性能优化等制造服务。
我国在今年推出“中国制造2025”“互联网+制造”战略的时候,也特别强调利用大数据为产业智能化提供支撑。
有一个对工业1.0到工业4.0变迁历史的总结非常精辟,借用一下:工业1.0是“工厂+机械”,利用机械替代人力,解放了生产力;工业2.0是“工厂+电”,通过电气化进一步提升生产效率;工业3.0是“工厂+电脑”,通过信息系统替代人工管理生产经营过程。那工业4.0是工厂+什么呢?顺着这个思路,3.0完成信息化之后,工厂经营生产的方方面面都已经有数据积累,再进一步的提升自然是基于这些数据进一步分析优化生产经营和探索数据驱动的新业务模式,因此,工业4.0就是“工厂+大数据”。



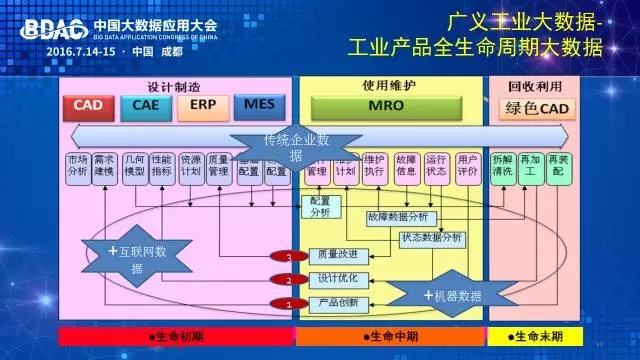
工业大数据从哪里来?来源于产品生命周期的各个环节,包括市场、设计、制造、服务、再利用各个环节,每个环节都会有大数据。“全”生命周期汇合起来的数据更大。当然,企业外、产业链外的“跨界”数据也是工业大数据“不可忽视”的重要来源。
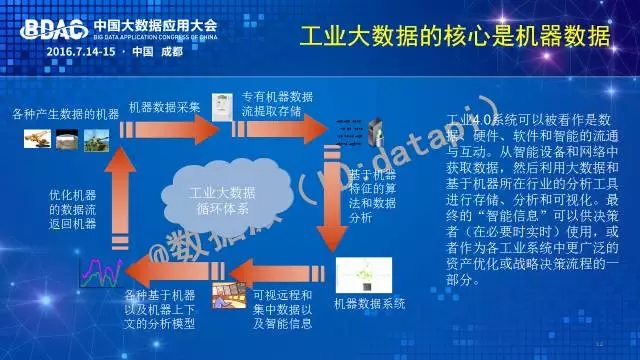
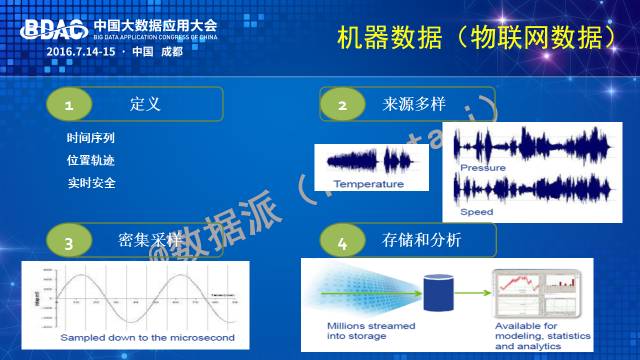


要利用好机器大数据,需要突破几类核心技术:
首先是数据怎么管理的问题。海量的机器型数据如时间序列、时空数据等高速采集完成后,需要把它存下来,这涉及到数据有效打包、压缩、放置的问题。数据存下来是为了被利用,这需要支持快速定位查询到应用需求的数据,而这又是一个如何建立高效的时空数据索引的问题。
数据存好管好了,下一个问题就是如何支持各种分析。做过实际分析的人都知道,分析绝不仅仅是开发一堆算法的问题。算法只是一小部分工作,大部分的工作是根据对业务问题的理解选取需要的数据,理解数据的特征,然后根据特征设计一个合适的模型和算法。这中间数据特征的理解对机器大数据来说是很难的。因为机器数据不能为人所直观理解,需要交互特征工程。此外,从模型和算法的层面,机器数据往往是对一个物理世界系统的感知结果,而物理世界有许多机理性的原理存在,比如机械领域涉及力学原理,冶金领域涉及化学原理,因此机器大数据的分析需要有机结合机理模型和数据统计模型。还有一个常常被忽略的问题是数据质量的问题——如何把握数据质量,如何修正数据质量。



未来的制造业要的不是石油,它最大的能源是数据.