学习数据分析,做大数据紧缺人才
AI 领域未来几年最引人瞩目的新方向是什么?
作者: 汶川
来源:学术头条
在调查近几年 AI 领域的过程中,我发现近几年对抗攻击的概念逐渐出现在全世界各国研究人员的视野中,我认为这将会是现在乃至未来几年最引人瞩目的新方向之一。
01 概述
我在国内的两个著名的学术搜索网站 AMiner 和 Acemap 进行了调查,以 adversarial attack 和相近意思的 poisoning attack 等词作为关键词搜索了相关的论文,以下是两个网站给出的论文数据分析图表。
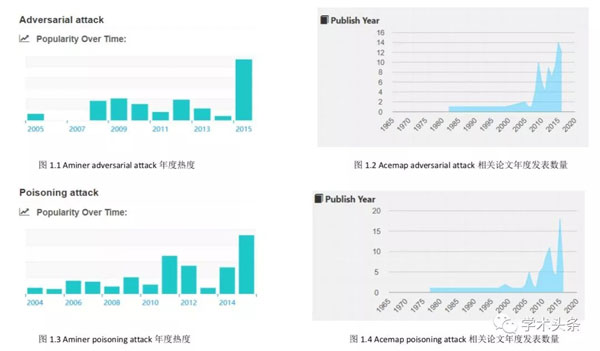
一方面,从图中很明显可以看出,在 2015 年直到今年,adversarial attack 相关的论文显著增多,这说明了在机器学习发展飞速的今天,机器学习的安全问题逐渐被研究者们所重视。 所以我认为这个方向在未来几年应该会是一个新兴的热点。
另一方面,虽然这类论文在近几年显著增多,但是这并不能说明这个方向的前景更好、 可挖掘的知识更多。所以我又搜索了另一个现在已经成为热门方向的领域——reinforcement learning 的数据来作为对比。
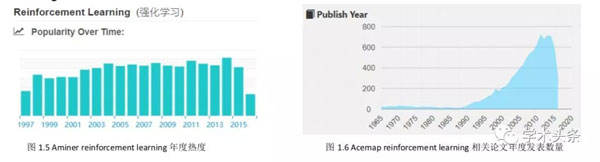
通过对比 reinforcement learning 和 adversarial attack 的热度和论文发表数量,可以发现与强化学习这类已经成为热门的方向相同,对抗攻击也开始有论文、热度急剧上升的阶段, 但是与之不同的是,对抗攻击论文的数量至今仍很少。
这说明了对抗攻击的可研究的东西还处于正在被研究者们逐渐挖掘的过程,还未形成一个体系。所以从这一点,直观上来说, 我认为最近的科技新词应当是 adversarial attack。
02 原理
对抗攻击的开山之作 Intriguing properties of neural networks[12] 中提到了神经网络的两个现象。
第一个是高维神经网络的神经元并不是代表着某一个特征,而是所有特征混杂在所有神经元中; 第二个是在原样本点上加上一些针对性的但是不易察觉的扰动,就很容易导致神经网络的分类错误。
第二个性质就是对抗攻击的理论基础,后来 Goodfellow 在 Explaining and Harnessing Adversarial Examples[13] 中提出原因并非是深层神经网络的高度非线性和过拟合,即使是线性模型也存在对抗样本。在这篇论文中,我们可以粗浅地认为对抗攻击之所以能够成功的原因是误差放大效应:

03 发展过程
在调研该领域的论文的过程中,我发现,作为 machine learning security 的方向,对抗攻击的发展可以归结为两个核心:不断寻找新的应用场景,不断利用新的算法

3.1 不断寻找新的应用场景
每当 machine learning 有新的领域出现,研究者都会试图在该领域上进行对抗攻击的研究,来研究出攻击这种领域的方法和防御的方法。以下是我找到的一些典型领域的对抗攻击研究成果:
3.1.1 Computer vision
·Attacks for classification
图片分类是计算机视觉最经典的任务,因此在这个应用场景的对抗攻击论文最多,比如: Jacobian-based Saliency Map Attack (JSMA)[1],One Pixel Attack[2],DeepFool[3] 等。
这些论文的思想都是相同的: 都是通过将图像的像素点按顺序或是随机一个一个改变,然后通过隐藏层的梯度来计算该点的改变对整张图片的攻击显著性并且根据梯度来选择下一个要改变的点,通过这样的训练最终可以找到最优的攻击像素。
其中,我认为 One Pixel Attack[2] 的工作效果最显著,这篇论文仅改变一个像素就能完成对整张图片的攻击。我认为最有新意的一点是,作者运用了差分进化算法的思想,通过每一代不断变异然后 “优胜劣汰”,最后可以找到足以攻击整张图片的一个像素点和其 RGB 值的修改值,这种方法的优点是属于黑盒攻击,不需要知道网络参数等任何信息。效果如下,我认为很显著:

·Attacks on Semantic Segmentation and Object Detection
语义分割任务的对抗攻击要比分类任务要难很多,语义分割的对抗样本生成 [4] 利用了 Dense Adversary Generation 的方法,通过一组 pixels/proposal 来优化生成对抗样本损失函数,然后用所生成的对抗样本来攻击基于深度学习的分割和检测网络。
这篇论文的亮点我认为在于将对抗攻击的概念转换为对抗样本生成的概念,将一个攻击任务转换为生成任务,这就给我们提供了一种新的攻击思路: 将这个任务转换为如何选取损失函数、如何搭建生成模型使得生成的对抗样本在攻击图片时有更好的效果。这种概念的转换使得对抗攻击不再拘束于传统的基于 FGSM 算法,也将更多的生成模型引入进来,比如 GAN。
我认为在计算机视觉的对抗攻击的局限在于,由于计算机视觉的子领域非常多,所以有一些领域还没有人去尝试过,而且由于深度学习的不可解释性,现阶段只能也通过深度学习去生成对抗样本去破坏目标的学习,这样的攻击是没有方向性的,比如无法控制分类任务的欺骗方向,我认为下一步的发展应在于如何去定向欺骗深度学习网络,来达到一些更高要求的目的。
3.1.2. Graph
在今年的 ICML 和 KDD 的论文中,有两篇关于对图结构的对抗攻击的论文,一篇是 Adversarial Attack on Graph Structured Data[5],另一篇是 Adversarial attacks on neuralnetworks for graph data[6]。这两篇论文都是对 graph 的攻击,这是以前从未有人做过的任务,是一种新的应用场景,因此前文我说对抗攻击发展还十分稚嫩,还在不断寻找新的应用场景。
由于 graph 结构数据可以建模现实生活中的很多问题,现在也有很多研究者在研究这种问题,比如知识图谱等领域。
拿知识图谱来举例,现在百度、阿里巴巴等公司都在搭建知识图谱,如果我能攻击知识图谱,在图上生成一些欺骗性的结点,比如虚假交易等行为,这会对整个公司带来很大损失,所以对图结构的攻击和防御都很有研究价值。
这两篇论文的出发点都是深度学习模型在图分类问题中的不稳定性。
第一篇论文定义了基于图模型的攻击: 在保持图分类结果不变的情况下,通过小规模的增加和减少边的方式, 较大化分类结果的错误率。基于此,论文提出了基于分层强化学习的方法来创建对抗样本。
第二篇论文的思想是对于要攻击的目标节点,产生一个干扰图,使得新图上的目标节点的分类概率和老图上目标节点的分类概率的差距较大,作者提出了 Nettack 的攻击模型。
我认为现阶段对图结构的对抗攻击的局限在于以下两点:
- 没有有效的防御算法。两篇论文都在讲如何去攻击图分类问题,但是对于防御问题, 第一篇论文只简单讨论了一下,比如随机 dropout,但是展示的结果很不理想,而第二篇论文根本没有讨论防御问题。因此对图结构的防御问题是接下来的一个可发展的方向。
- 现阶段图深度学习发展还不完善,没有形成一个像图片卷积神经网络那样的完整体系,GCN、随机游走等算法都各有利弊,所以在整个体系完成之前,对抗攻击的发展方向不是很明朗。我个人觉得随着可微池化 [7] 的概念的提出,GCN 应该是以后图深度学习的发展方向,所以对 GCN 的攻击或许很有潜力。
3.1.3 其他领域的对抗攻击
近期也有一些其他领域的对抗攻击。
首先,Adversarial Examples for Evaluating Reading Comprehension Systems[8] 这篇论文对 QA 系统进行对抗攻击,通过向问题中中加入不影响人类理解并且不影响正确答案的句子来欺骗问答系统,来获得错误的答案。论文中给出的结果很显著,使原先 75% 的 F1 score 下降至 36%,如果允许不符合语法规则的话可以下降至 7%。
其次,对于强化学习的对抗攻击。Lin 等 [9] 提出了两种不同的针对深度强化学习训练的代理的对抗性攻击。在第一种攻击中,被称为策略定时攻击,对手通过在一段中的一小部分时间步骤中攻击它来最小化对代理的奖励值。提出了一种方法来确定什么时候应该制作和应用对抗样本,从而使攻击不被发现。在第二种攻击中,被称为迷人攻击,对手通过集成生成模型和规划算法将代理引诱到指定的目标状态。生成模型用于预测代理的未来状态,而规划算法生成用于引诱它的操作。这些攻击成功地测试了由较先进的深度强化学习算法训练的代理。
还有一些对于 RNN, Speech Recognition 等领域的攻击 [10][11],这些领域的对抗攻击基本上只有一两篇。
综上所述,对于对抗攻击的应用场景,现阶段所发掘的只不过是冰山一角,在这个领域, 还有很多很多应用场景可以进行研究。因此,仅从应用场景而言,对抗攻击是最近几年最具潜力的方向。
3.2 算法
对抗攻击的本质是用机器学习的方法去攻击机器学习模型,来检测模型的鲁棒性。由于它的攻击目标和自身所用的方法都是机器学习,所以当机器学习领域出现了更好的算法时,对于对抗攻击而言,这既是新的应用场景,又是自身可用的新算法。
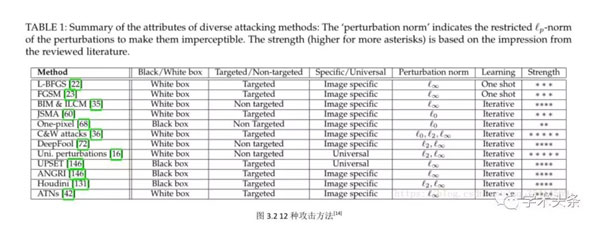
在 Threat of Adversarial Attacks on Deep Learning in Computer Vision: A Survey[14] 这篇论文中总结了 12 种攻击方法,如下图所示:
经过我的调研,在论文 Adversarial Examples for Semantic Segmentation and Object Detection[4] 的启发下,我认为,既然对抗攻击是对抗样本的生成任务,而生成任务又是现在发展非常迅速的一个领域,我们可以把一些生成模型迁移到这个任务上来。
比如,现在非常热门的对抗生成网络 GAN 是生成任务最有效的模型之一,我认为可以借用这种对抗的思想生成对抗样本: 一个专门向原数据中加噪声的网络和一个试图根据对抗样本完成分类任务的网络,两个网络就像 GAN 里面的生成器和鉴别器一样对抗学习,最后会收敛于加噪声的网络生成的对抗样本足以迷惑分类网络,这样生成的对抗样本或许会比前文所述的方法效果更好。
由于生成任务还在不断发展,VAE、GAN 等模型或许都可以用于对抗攻击,近期新出现的 CoT[15](合作训练) 为离散数据的生成任务也提供了一种新的思路,Glow[16] 提出了基于流的可逆生成模型,据说效果会超过 GAN...... 这些生成模型不断在发展,可供对抗样本生成借鉴的思路也越来越多,所以,我认为在算法上对抗攻击还有无限的潜力。
04 总结
经过对对抗攻击的调研,首先,我发现这一领域的论文数很少,而且受大众的关注度不是很高,但是对抗攻击已经有趋势要迎来蓬勃发展的时期了。
其次,对抗攻击还处于寻找新的应用场景和不断尝试新的算法的阶段,还不成熟,未形 成完整的体系,而且和攻击与生俱来的还有防御问题,现阶段防御问题基本还处于把对抗样本加入原始数据一起训练以此来防御攻击的状态,研究的人很少,也没有十分显著的效果。 这说明在这个领域还有很大的可挖掘的空间。
在机器学习发展飞速的今天,安全性问题正逐渐进入人们的的视野,对抗攻击不只能够在网络空间进行攻击,还能够在物理世界中任何使用到机器学习的场景中进行有效攻击,比如针对人脸识别、语音识别的攻击。为了机器学习更好的发展,研究对抗攻击是有必要的。 因此我认为最近的科技新词是 adversarial attack。
引用:
[1] N. Papernot, P. McDaniel, S. Jha, M. Fredrikson, Z. B. Celik, A.Swami, The Limitations of Deep Learning in Adversarial Settings, In Proceedings of IEEE European Symposium on Security and Privacy, 2016.
[2] J. Su, D. V. Vargas, S. Kouichi, One pixel attack for fooling deep neural networks, arXiv preprint arXiv:1710.08864, 2017.
[3] S. Moosavi-Dezfooli, A. Fawzi, P. Frossard, DeepFool: a simple and accurate method to fool deep neural networks, In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2574-2582, 2016.
[4] C. Xie, J. Wang, Z. Zhang, Y. Zhou, L. Xie, and A. Yuille, Adversarial Examples for Semantic Segmentation and Object Detection, arXiv preprint arXiv:1703.08603, 2017.
[5] Dai, Hanjun, Hui Li, Tian Tian, Xin Huang, Lin Wang, Jun Zhu, and Le Song. "Adversarial Attack on Graph Structured Data." In International Conference on Machine Learning (ICML), vol. 2018. 2018.
[6] Zu?gner, Daniel, Amir Akbarnejad, and Stephan Gu?nnemann. "Adversarial attacks on neural networks for graph data." In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp. 2847-2856. ACM, 2018.
[7] Ying R, You J, Morris C, et al. Hierarchical graph representation learning with differentiable pooling[J]. CoRR, 2018
[8] Jia R, Liang P. Adversarial examples for evaluating reading comprehension systems[J]. arXiv preprint arXiv:1707.07328, 2017.
[9] Y. Lin, Z. Hong, Y. Liao, M. Shih, M. Liu, and M. Sun, Tactics of Adversarial Attack on Deep Reinforcement Learning Agents, arXiv preprint arXiv:1703.06748, 2017.
[10] Papernot N, McDaniel P, Swami A, et al. Crafting adversarial input sequences for recurrent neural networks[C]//Military Communications Conference, MILCOM 2016-2016 IEEE. IEEE, 2016:49-54
[11] Carlini N, Wagner D. Audio adversarial examples: Targeted attacks on speech-to-text[J]. arXiv preprint arXiv:1801.01944, 2018.
[12] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, R. Fergus, Intriguing properties of neural networks, arXiv preprint arXiv:1312.6199, 2014.
[13] I. J. Goodfellow, J. Shlens, C. Szegedy, Explaining and Harnessing Adversarial Examples, arXiv preprint arXiv:1412.6572, 2015.
[14] Akhtar N, Mian A. Threat of adversarial attacks on deep learning in computer vision: A survey[J]. arXiv preprint arXiv:1801.00553, 2018
[15] Lu S, Yu L, Zhang W, et al. CoT: Cooperative Training for Generative Modeling[J]. arXiv preprint arXiv:1804.03782, 2018.
[16] Kingma D P, Dhariwal P. Glow: Generative flow with invertible 1x1 convolutions[J]. arXiv preprint arXiv:1807.03039, 2018.

未来的制造业要的不是石油,它最大的能源是数据.