年终盘点:2017年数据科学发展的新趋势
作者: 田晓旭
2001年,Gartner给出了大数据的概念,即大数据是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力来适应海量、高增长率和多样化的信息资产。这其中点出了大数据关键的3V特征,即海量、速度和多样性,也很明确的为我们指出了大数据在哪些方面存在挑战。但是,16年过去了,现在大数据发展仍然没有达到边界,还是一个充满想象力的领域。
因为数据的存在,让很多新的行业焕发出了无限的价值,社交媒体网站可能就是一个典型的例子。对于企业来说,目前的主要问题就是如何使用收集来的数据创造价值。为此,Dzone社区调查了734个和大数据相关的技术人员,下面我们就来看看有哪些有趣的结论。
开源仍然是大趋势
开源是整个IT技术的大趋势,在大数据领域也不例外。据Dzone的相关调查,71% 的受访者都在使用开源工具进行数据科学的相关工作,只有16%的人在使用商业工具。开源工具在个人开发项目和企业应用程序中得到了快速应用。
2016年曝光度最高的开源工具Spark,今年的采用率从去年的31%增长到了45%。而今年曝光率最高的开源工具,TensorFlow绝对算得上一号,自谷歌一年半之前发布以来TensorFlow的采用率已经达到17%。
开源工具的出现让大数据的应用推进的更快,如果不能快速适应上手新的开源工具,那么关于数据科学的相关工具就无法开展。
Apache Hadoop仍然是领头羊
前几天,有的专家在预测数据库未来发展趋势时,提出了一个观点那就是“Hadoop将死”,但是通过具体的数据,我们发现Apache Hadoop现在仍然有实力强劲。65%的数据工程师都正在使用或者曾经使用过Apache Hadoop。47%的技术人员使用Yarn进行集群管理。62%使用Apache ZooKeeper,55%使用Hive来做数据仓储。
得益于MapReduce处理和存储数据的能力,自2011年发布以来,Apache Hadoop就一直呈现着高速发展的趋势,现在广受欢迎的众多先进工具都是建立在Hadoop之上。对于开发者和数据科学家来说,Hadoop是一盏明灯,有助于他们在未来职业中的晋升。
当然,为了克服MapReduce的局限性,Apache Spark应运而生,同时还衍生出一些其他的新技术,例如 Spark SQL、GraphX、 MLib和 Spark Stream等等。
数据库的发展
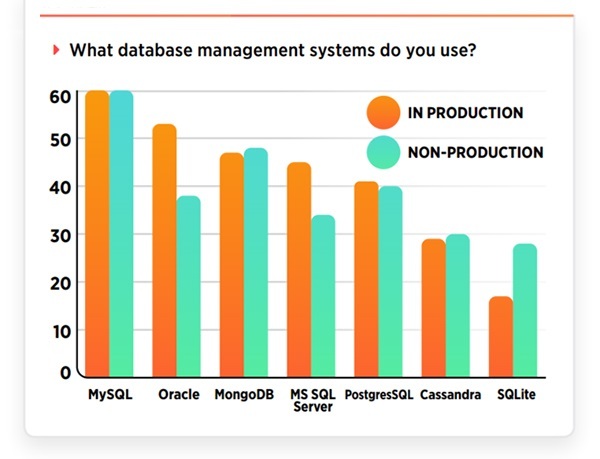
关于数据库的发展,今年并没有大格局的变化。据Dzone的调查,MySQL被60%的受访者应用于生产和非生产的环境中。MongoDB被47%的受访者应用于生产环境中,48%应用于非生产环境中,PostgreSQL被41%的受访者应用于生产环境中和40%应用于非生产环境中。
而商业数据库可能是由于许可证的问题,似乎并不如开源数据库那么受欢迎。而其他一些数据库,例如SQLite这样轻量级的数据库也会占据一定的份额。但是NoSQL数据库的发展则越来越稳健,有56%的数据科学从业人员选择使用NoSQL。
编程语言、工具、库和框架
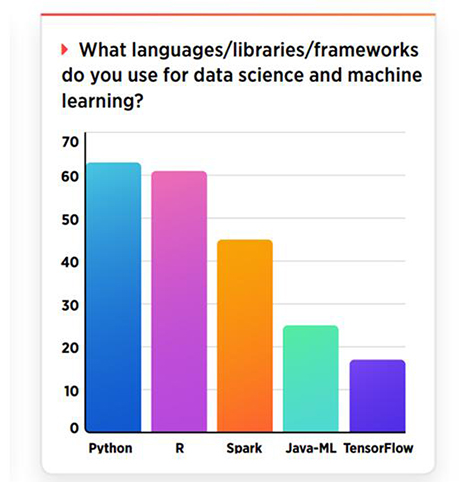
数据科学其实很大程度上都依赖开源的编程语言、工具、库和框架。就编程语言来说,Python和R都是数据科学的热门语言。相比较于R语言来说,Python可能更受欢迎一些,其在受访者中获得了63%的支持,而R语言则获得了61%的支持。
而对于框架来说,Spark Stream在流数据计算框架中颇受欢迎,在数据采集过程中Kafka得到了54%的支持。剩余其它的一些框架则没有得到超过25%的支持率,不过,这其中还有一匹黑马,那就是GraphX,其在迭代图处理类别中获得了24%的支持率。
来源:IT168

未来的制造业要的不是石油,它最大的能源是数据.